Direct Preference Optimization
Abstract:
- RLHF is complex and often unstable
- requires fitting a reward model first
- fine-tune LM with RL, without drifting too far from pre-training.
DPO - new parametrization of reward model in RLHF, allows optimal policy in closed form, train with classification loss.
- Stable, performant, lightweight computationally.
-
Don’t need to sample from the LM during fine-tuning.
- DPO > PPO in sentiment control, equal or better in response quality, single-turn dialogue
LMs
- LMs trained on all sorts of garbage data, e.g. bad code - want to bias towards the rare ‘good code’ examples. Or, misconceptions that 50% of people believe - bias toward truth.
- select responses and behavior from knowledge and abilities.
-
RL objectives simplify to BCE.
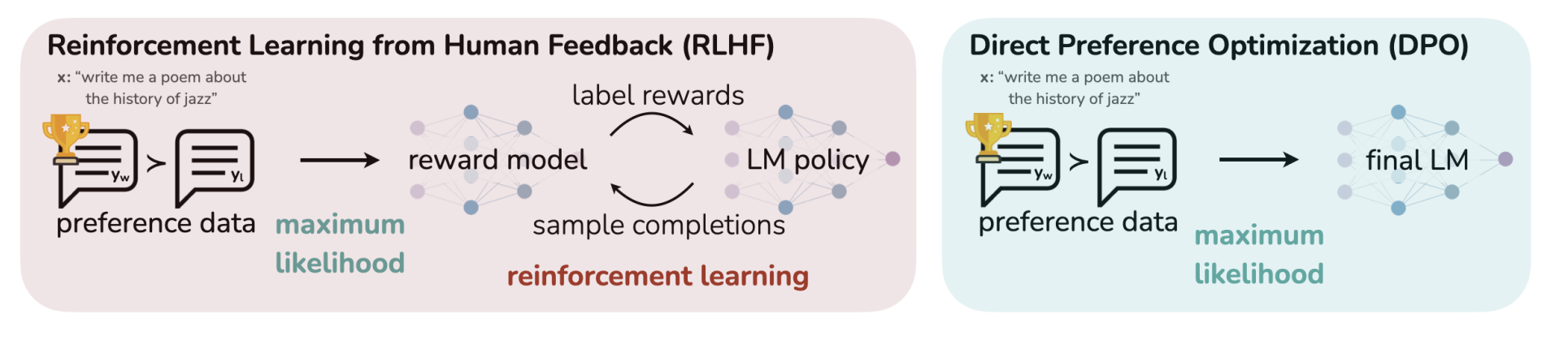
- RL typically does better than SFT on human demonstrations
- RLHF requires training another LM as reward model
- contains loss to prevent drifting too much from original model