Backpropagation
CS 231 Notes
Notes on Derivatives
Derivative = sensitivity to an input. $\frac{df}{dx} = 3$ means changes in $x$ will change $f$ by 3 times that amount.
$x$ increasing by $h$ results in change $\frac{df}{dx} * h$.
$f(x+h) \approx f(x) + h \frac{df}{dx}$
$f(x,y) = \max(x,y), \frac{df}{dx} = 1[x \geq y], \frac{df}{dy} = 1[y \geq x]$
only the higher value matters, gradient is zero on the lower value.
Notation
- Always assume $dq$ implies $\frac{df}{dq}$ or $\frac{dL}{dq}$.
- the computation is a bunch of gates -
- computes inputs to outputs
- computes $dout$ to derivatives with respect to inputs
- local graient means gradient with respect to gate’s output, or $\frac{dout}{din}$.
- the “upstream gradient” is $\frac{dL}{dout}$.
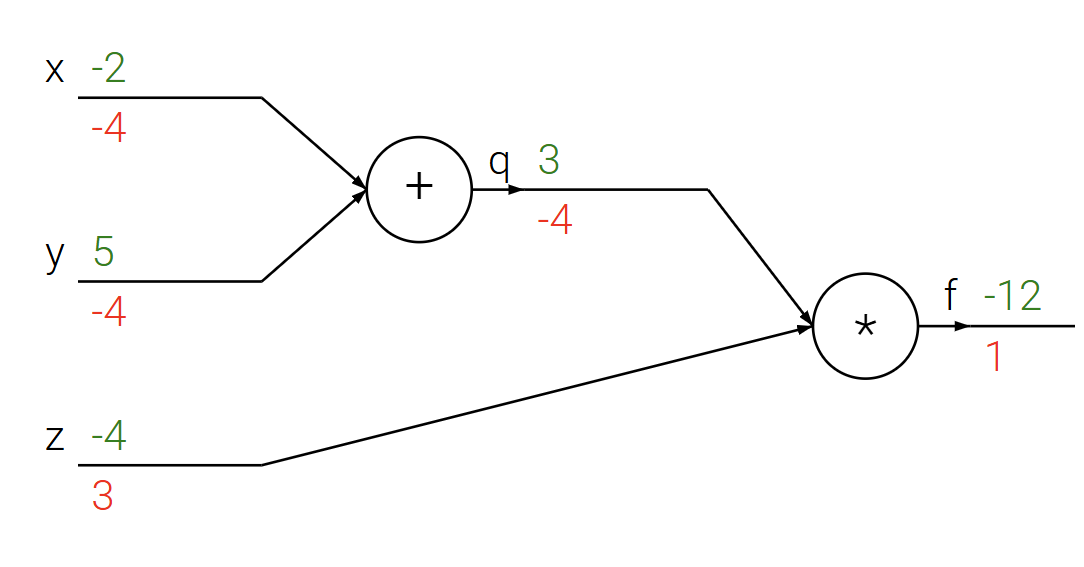
In this graph, green is activations, red is derivatives. To increase $f$ by 1, we must decrease $q$ with a force of $-4$.
This multiplies $\frac{dx}{dq}$ by $-4$.
Gates are determined by convenience.
Backpropagation is gates communicating how to increase the output.
Backpropogation
- just think of the one-input, one-output gradient, using the total derivative. then broadcast this operation. don’t need to think of it as matrix multiplies, as this gets harder when the dimensionality increases.
-there are local gradients, and upstream gradients (dout/din, dL/dout). you always do a sum reduction across this dimension.
-grouping operations in a single gate for simplicity
-this combines with the branching rule.
- need to cache forward pass variables, if you do things one step at a time
- plus gates always route gradients to its inputs equally, max gates routes the gradient to the bigger value, and multiply gates take input activations, multiply them by the gradient of the multiply gate’s output, and swaps them. -the multiply gate assigns the bigger gradient to the tiny input - so, if you multiply the input values by 1000x in linear classification, the weight has a very large affect on the output, and you will need to lower the learning rate. that is why preprocessing is important.
Vector Matrix Derivatives
Vector Matrix derivative: https://cs231n.stanford.edu/vecDerivs.pdf -taking derivatives of multiple things simultaneously, applying the chain rule, and taking derivatives when there is a summation - split these things up -write the formula for a single element of the output in terms of scalars -remove summation notation
Speeding things up when coding
If you imagine things like scalars, things should make sense. For instance, in batchnorm, the last part of the forward is
out = x_hat * g[:, None, None] + b[:, None, None]
The backward is: dL_db = np.sum(dL_dout, axis=(0, 2, 3)) dL_dg = np.sum(dL_dout * x_hat, axis=(0, 2, 3)) dL_dx_hat = dL_dout * g[:, None, None]
besides the sums, this looks like what it should be if we used the scalar chain rule.
The sums exist due to broadcasting - instead of an elementwise multiply, the same values of b is broadcast to the H, W, and N axes.
For instance, we can imagine copying g to g_tiled, which is shape of (N, C, H, W). Then the gradient of g_tiled would simply be dL_dout * x_hat, since we are just doing elementwise multiplication. But, then we gotta ‘pile up’ these gradients, to see the gradient on g, which is of shape (C,) Therefore, we have to sum across the N, C, H, W axes.
Treating everything like a scalar, then summing/broadcasting when appropriate works for most broadcasted operations, like summing and multiplying.
It gets more complicated when you do something like softmax, but you can always reduce it to smaller steps.
But most of the time, you can broadcast the upstream gradient when doing the multiplication for the chain rule, then sum appropriately to get the right shape